Apache Pulsar is a cloud-native, open-source distributed streaming and messaging platform. Yahoo designed the system to fulfill the need for durability and scalability. One of its unique and critical components is the Apache Pulsar Schema.
A schema defines a data structure that a message should follow to be understood and processed across a network. Essentially, it provides a blueprint of how the message should look.
Initially, data streaming did not use a schema; raw bytes were efficient and neutral vehicles. However, developers had to overlay their serialization mechanisms to ensure that processes on the receiving end were able to read and interpret the bytes fed into the system. This situation required creating an extra layer to monitor bytes flowing through the system.
Another challenge that raw bytes presented was the pipeline’s inability to cope with changes in data structures. If a developer slightly changes a field, the entire system starts throwing errors because the end systems’ binaries store all information related to structures.
Pulsar Schema solved all of these problems by introducing a new sender-receiver coordination mechanism. It has since become a system of choice for many developers. Verizon, Tencent, Comcast, Overstock.com, and numerous other enterprises have adopted this method.
In this article, we’ll examine how Pulsar Schemas work and contrast them with schemaless systems to determine the best approach. We’ll also demonstrate how to use Java clients with Pulsar.
How Schemas Work
Pulsar Schemas have two endpoints: a producer side that sends data and a consumer side that receives data. The two connect through brokers that communicate with the back-end processes.
Although the producer and consumer don’t connect directly, a contract specifies that the data a producer writes should follow a schema that a consumer can read. A schema registry enforces this contract by verifying the compatibility of schemas that each forwards to the brokers. It applies and enforces Pulsar Schemas at the topic level.
A topic is just an abstraction in the form of a Uniform Resource Identifier (URI). It groups messages based on context. A topic structure looks like this:
{type}://{tenant}/{namespace}/{topic}
How a Schema Works on the Producer Side
Before a producer sends data, it forwards the schema info to a broker. The broker checks the schema storage to verify that the received schema has been registered. The broker sends the schema version back to the producer if it is registered. If it is not registered, the broker checks whether it can automatically generate the schema in that namespace. If possible, the broker creates a schema, registers it, and returns the schema version to the producer. If it is not possible, it rejects the connection to the broker. Below is a producer-side schema verification chart: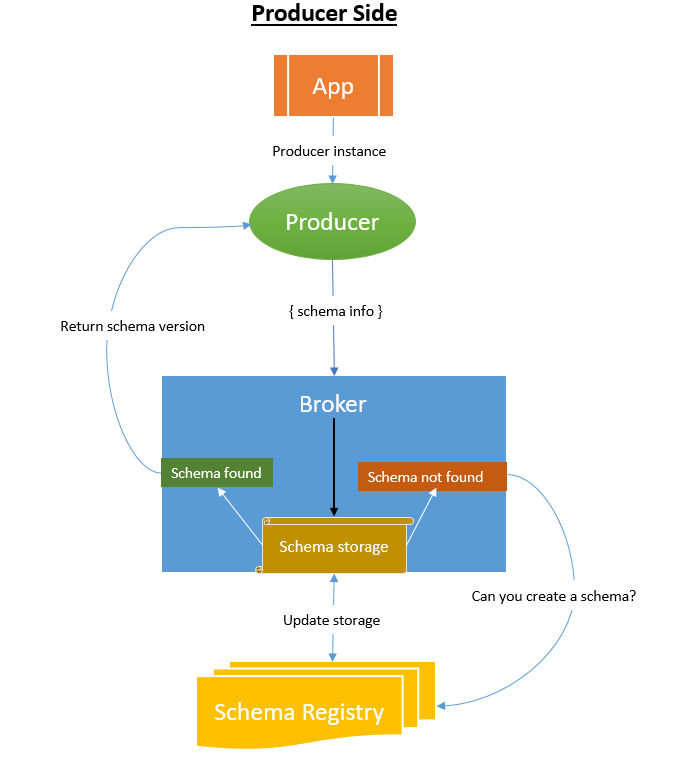
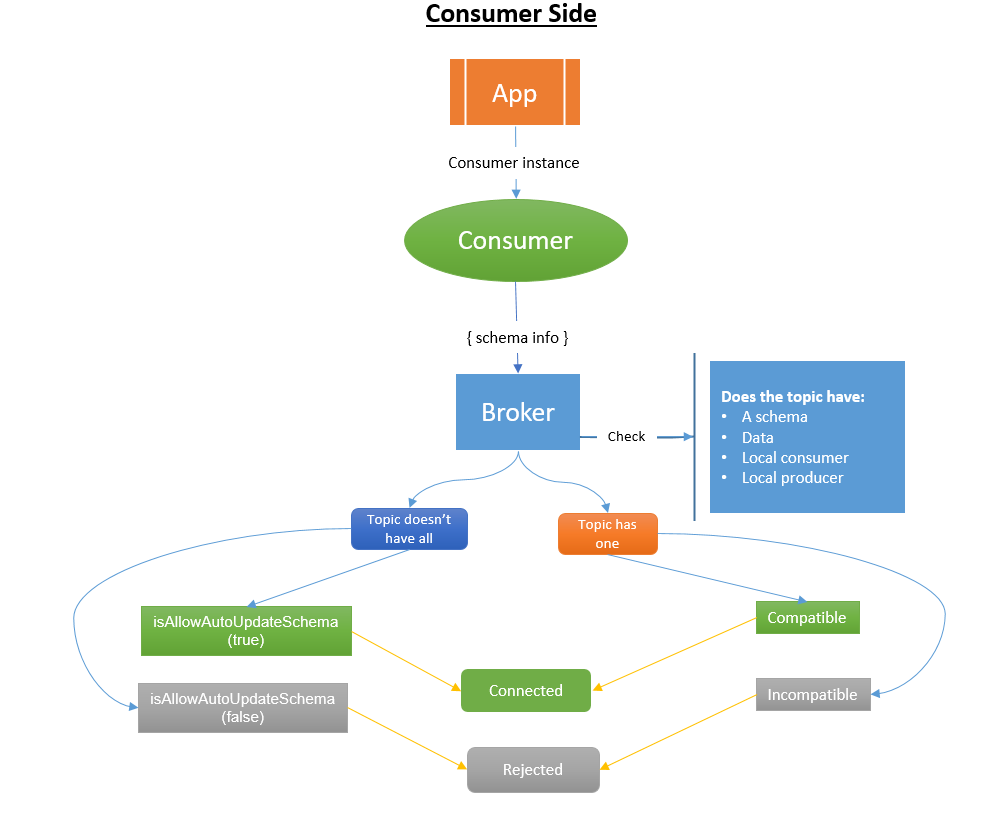
How a Schema Works on the Consumer Side
First, the application uses a schema instance to create a consumer instance that has the schema info. The consumer then forwards the schema information to the broker.
The broker checks if the topic has any of the following:
- A schema
- Data
- A local consumer
- A local producer
If it doesn’t contain them all and isAllowAutoUpdateSchema is set to true, the broker registers the schema and the consumer connects to the broker. If isAllowAutoUpdateSchema is false, the broker rejects the connection.
If the schema only has one of the listed components, the broker performs a schema compatibility check. If it is compatible, the consumer is allowed to connect to the broker. The broker rejects the connection if it doesn’t pass the compatibility check.
When to Use Schemaless
A Pulsar instance natively supports multiple clusters. It can seamlessly geo-replicate messages across clusters and scale out to more than a million topics with low latency.
Nonetheless, schemas are not a one-size-fits-all solution. In some cases, schemaless is more efficient and sustainable.
Consider a situation wherein we want to manage documents instead of uniform data structures. If we have documents in JSON with fields that are not uniform, we want a flexible solution that can adjust accordingly.
Using Java Clients with Pulsar
We have explored how a consumer and producer communicate with a schema registry. Now, we’ll create a Java application that uses Apache Pulsar.
We’ll start by creating a Maven project that contains an Apache Pulsar client as a dependency:
<dependencies>
<dependency>
<groupId> org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
Adding a Producer
Before we can create a producer, we must initiate the Pulsar client using this code:
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:8080")
.build();
We can now create a producer client that is attached to a topic. We’ll use the Pulsar client we created above to initiate the new producer client:
Producer<String> producer = pulsarClient.newProducer(Schema.STRING)
.topic("fun-topic")
.create();
At this point, the broker will block the send() method until the schema registry verifies the schema. After the broker sends an acknowledgment, we can call the send() function like this:
producer.send("Hello there!");
After that, we close the producer using this code:
producer.close();
Adding a Consumer
We’ll use the Pulsar client to create a new consumer. In this example, we’ll create an exclusive consumer specified by subscriptionType():
Consumer<String> consumer = pulsarClient.newConsumer(Schema.STRING)
.topic("fun-topic")
.subscriptionName("fun-subscription")
.subscriptionType(SubscriptionType.Exclusive)
.subscribe();
receiver() in a while loop to fetch any produced messages in the subscribed topic:
while (true) {
Message<String> myMessage = consumer.receive();
try {
System.out.printf("Here is the message: %s", myMessage);
consumer.acknowledge(myMessage);
} catch (Exception e) {
consumer.negativeAcknowledge(myMessage);
}
}
acknowledge(). It also sends an alert if it fails by invoking negativeAcknowledge().
That is all that’s required. We now have a simple Java application that communicates to Pulsar using a Pulsar client.
Pulsar Schema’s Pros and Cons
Schema Pros
- Pulsar stamps every piece of data passing through its system with a name and schema version. This makes all data passing through the system easily discoverable.
- Schema provides an easy way for producers and consumers to coordinate their data structure. If the producer’s schema changes, the registry ensures it is compatible with the old consumer schemas. This approach enables us to create systems that can adapt to data structure changes without the message pipeline failing.
Schema Cons
- Schemas are relatively restrictive. We must know the data structure beforehand.
Schemaless Pros and Cons
Schemaless Pros
- Schemaless approaches are efficient and neutral to the data they transmit.
- They enable us to create a streaming pipeline even when the data structure is unclear.
Schemaless Cons
- Data structures are stored locally on both ends, making it challenging to synchronize them with one another.
- Schemaless requires significant work to change the data structure.



